Instance Segmentation for Cataract Surgery Videos Dataset(s)
Here you find two datasets for Instance Segmentation based on Cataract Surgery Videos, that were created for content-based video analysis (i.e. surgical tool detection). The annotations for the images in both datasets are in COCO-Format and were created manually (dataset 1) / automatically (dataset 2).
Dataset 1
This is a careful selection of frames out of our public collection of cataract surgery videos [1], that was manually annotated using COCO-annotator. In the selection process we focused on frames with the best visual quality (e.g. no blurriness) and made sure to have a variety of different poses for each class. The final dataset at publication includes annotations for 9 important instruments used in the widely-used COCO-Format. In total we have annotated 393 different images. The classes are balanced and you will not find images of the same video across the sets.
UPDATE, October 2020:
We have extended this dataset with additional images (of better quality) and added missing instrument classes.
The full dataset now consists of 843 annotated images and 11 classes.
You find the newest version of the dataset by downloading InSegCat dataset 1 v2.0.
Instrument classes
The following class mapping is found in dataset 1:
- i1: slit knife
- i2: angled incision knife
- i3: katena forceps
- i7: 27 gauge cannula
- i8: capsulorhexis forceps
- i9: cannula
- i10: phaco tip
- i11: spatula
- i12: I/A handpiece
- i16: cartridge
- i20: eye retractors
Examples
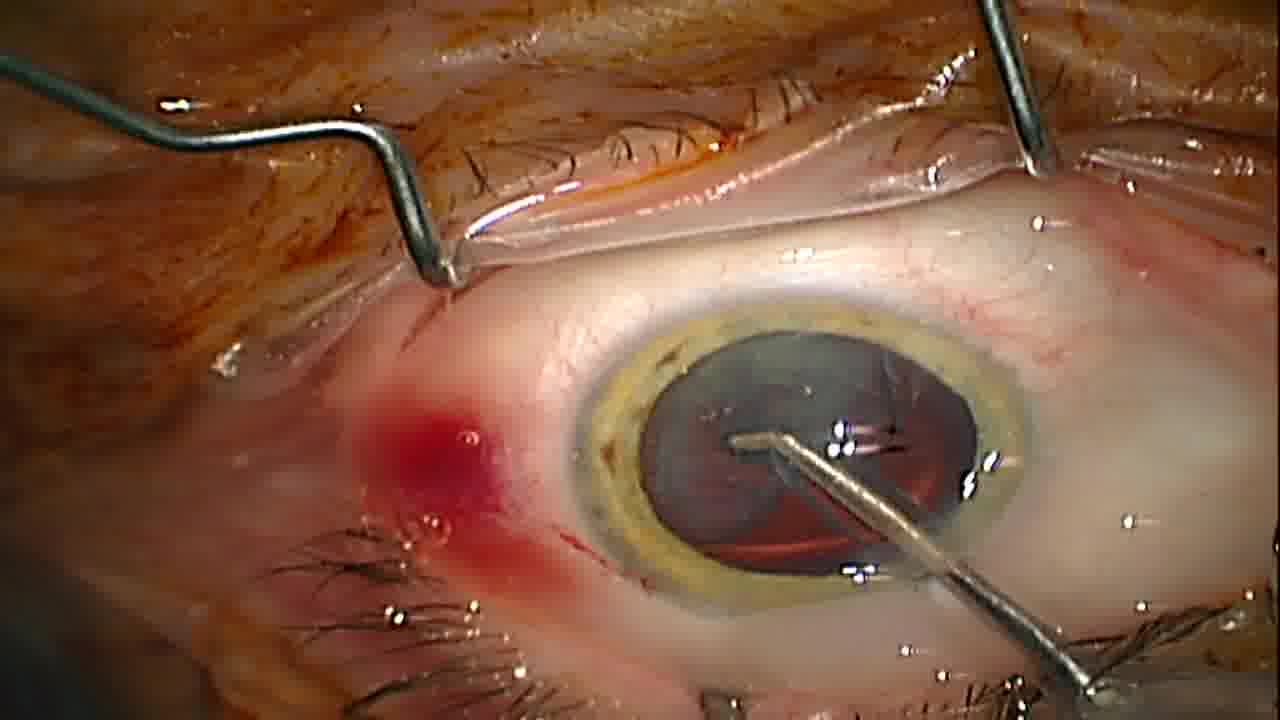
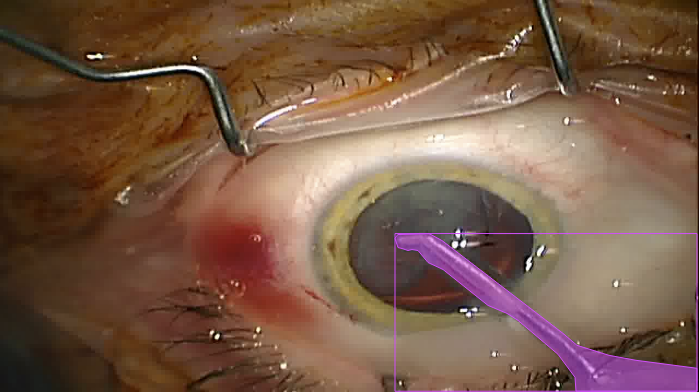
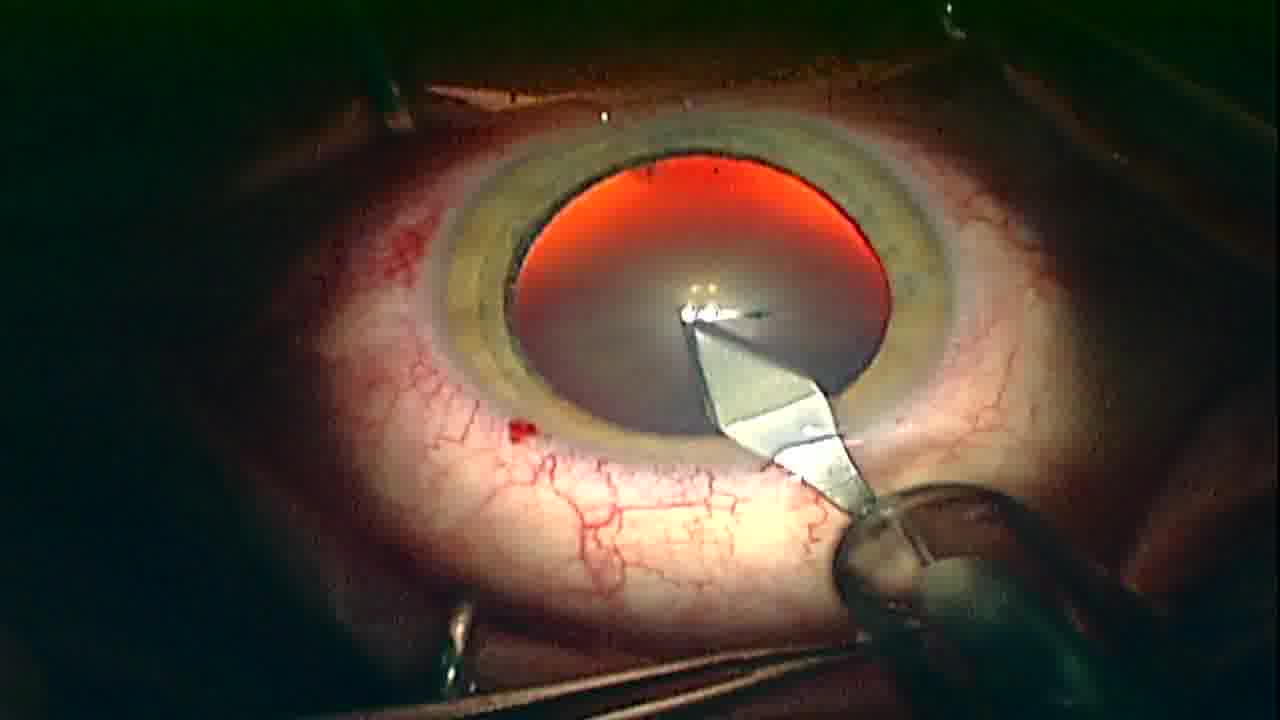
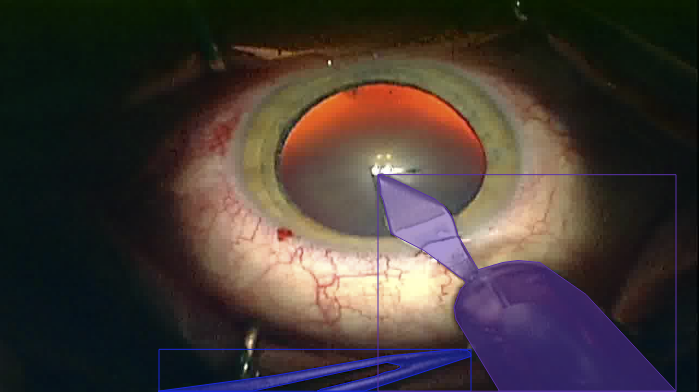
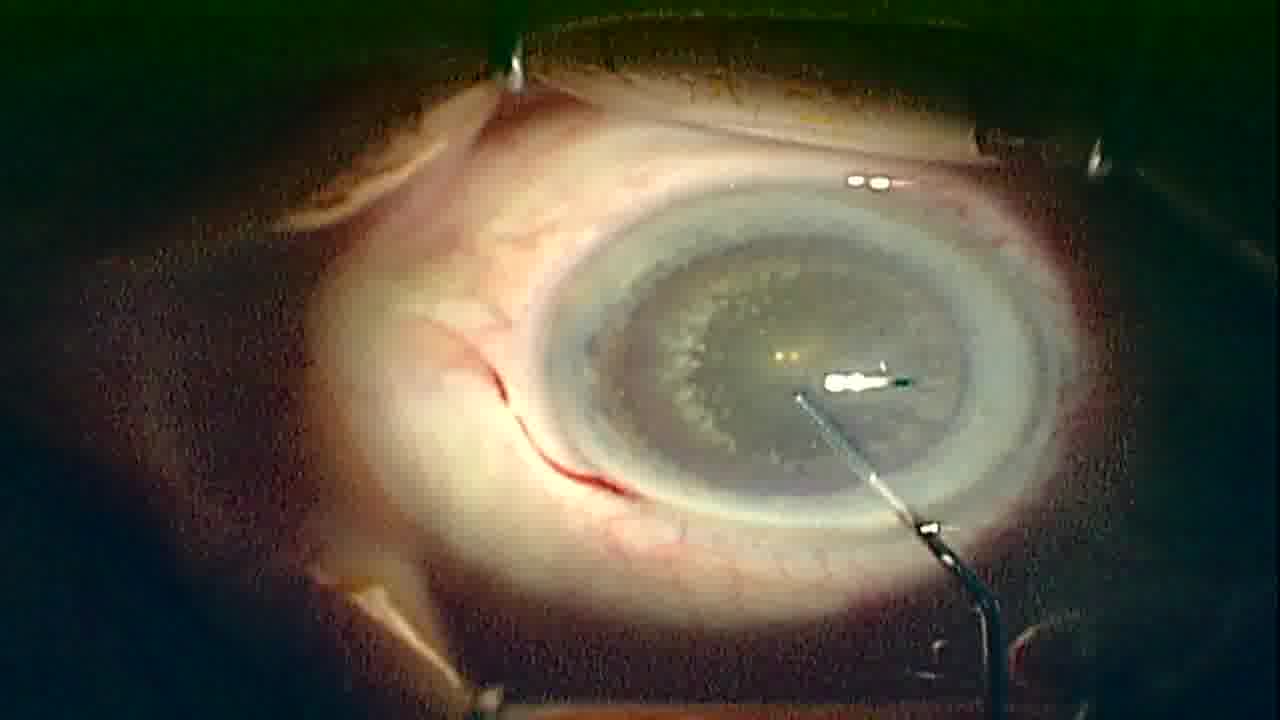
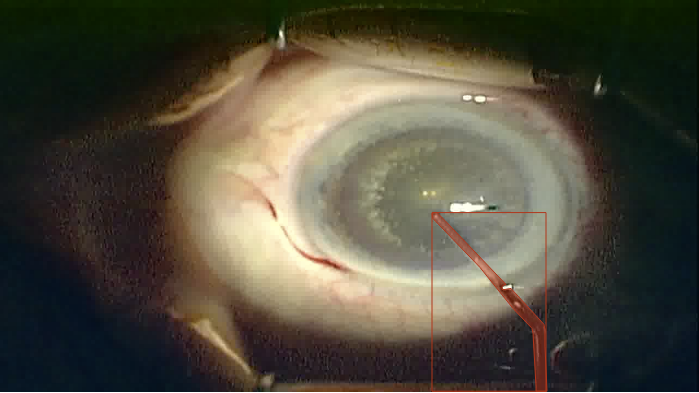
Dataset 2
For dataset 2 we converted the information provided with the public CaDIS-dataset for Image Segmentation [3] from a Semantic Segmentation task to an Instance Segmentation task by taking the existing mask-images and extracting bounding-boxes as well as instance masks of the desired classes. As a result this dataset is 9x larger than dataset 1 and of the same format. In total there are 4738 annotated images and we keep the same split for training-/validation-/testset images as found in the original format: 3582 training, 542 validation and 614 testing.
Instrument classes
The following classes are annotated in the dataset:
- A/I handpiece
- Bonn forceps
- Cap. cystotome
- Cap. forceps
- Charleux cannula
- Hydro. cannula
- Lens injector
- Micromanipulator
- Phaco. handpiece
- Primary knife
- Rycroft cannula
- Secondary knife
- Suture needle
- Visco. cannula
- Viter. handpiece
Annotations
Original images and mask images were taken from CaDIS-dataset and Annotations were generated by us.
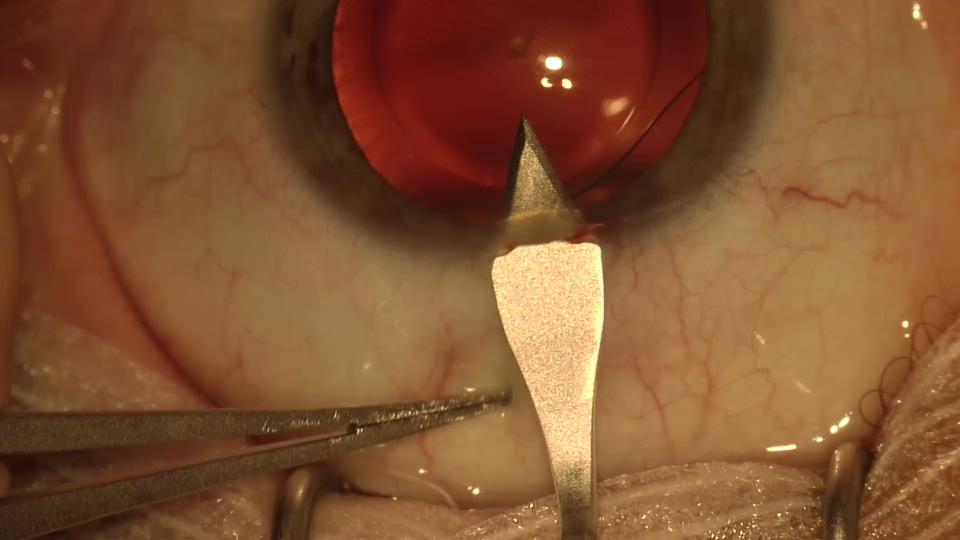
Original image

Mask image

Annotated image
Disclaimer
The datasets are exclusively provided for scientific research purposes and as such cannot be used commercially or for any other purpose. If any other purpose is intended, you may directly contact the originator of the videos, Assoc. Prof. Dr. Klaus Schöffmann.
In addition, reference must be made to the following publication [2] when this dataset is used in any academic and research reports:
M. Fox, M. Taschwer, K. Schoeffmann. 2020. Pixel-Based Tool Segmentation in Cataract Surgery Videos with Mask R-CNN. IEEE 33rd International Symposium on Computer Based Medical Systems (CBMS). DOI:10.1109/CBMS49503.2020.00112
* Images of dataset 2 are taken from the CaDIS-dataset, hence, when utilizing this dataset you are requested to as well refer to Flouty et al [3].
@inproceedings{DBLP:conf/cbms/FoxTS20,
author = {Markus Fox and
Mario Taschwer and
Klaus Schoeffmann},
editor = {Alba Garc{\'{\i}}a Seco de Herrera and
Alejandro Rodr{\'{\i}}guez Gonz{\'{a}}lez and
K. C. Santosh and
Zelalem Temesgen and
Bridget Kane and
Paolo Soda},
title = {Pixel-Based Tool Segmentation in Cataract Surgery Videos with Mask
{R-CNN}},
booktitle = {33rd {IEEE} International Symposium on Computer-Based Medical Systems,
{CBMS} 2020, Rochester, MN, USA, July 28-30, 2020},
pages = {565--568},
publisher = {{IEEE}},
year = {2020},
url = {https://doi.org/10.1109/CBMS49503.2020.00112},
doi = {10.1109/CBMS49503.2020.00112},
timestamp = {Thu, 10 Sep 2020 16:38:14 +0200},
biburl = {https://dblp.org/rec/conf/cbms/FoxTS20.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
The datasets are licensed under Creative Commons Attribution-NonCommercial 4.0 International (CC BY-NC 4.0,  ) and is created as well as maintained by Distributed Multimedia Systems Group of the Institute of Information Technology (ITEC) at Alpen-Adria Universität in Klagenfurt, Austria.
) and is created as well as maintained by Distributed Multimedia Systems Group of the Institute of Information Technology (ITEC) at Alpen-Adria Universität in Klagenfurt, Austria.
This license allows users of this dataset to copy, distribute and transmit the work under the following conditions:
- Attribution: You must give appropriate credit, provide a link to the license, and indicate if changes were made. You may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
- Non-Commercial: You may not use the material for commercial purposes.
Download
If you agree to above conditions, you are free to download:
- InSegCat dataset 1 v2.0 (~176MB).
- InSegCat dataset 2 (~3.04GB).
References
[1] K. Schoeffmann, M. Taschwer, S. Sarny, B. Münzer, M.J. Primus, and D. Putzgruber. Cataract-101: video dataset of 101 cataract surgeries. In Proceedings of the 9th ACM Multimedia Systems Conference, pages 421–425. ACM, 2018.
[2] M. Fox, M. Taschwer, K. Schoeffmann. 2020. Pixel-Based Tool Segmentation in Cataract Surgery Videos with Mask R-CNN. To appear: IEEE 33rd International Symposium on Computer Based Medical Systems (CBMS).
[3] E. Flouty, A. Kadkhodamohammadi, I. Luengo, F. Fuentes-Hurtado, H. Taleb, S. Barbarisi, G. Quellec, and D. Stoyanov. Cadis: Cataract dataset for image segmentation.